- Product Upfront AI
- Posts
- This AI just got smarter, faster, AND cheaper (all three)
This AI just got smarter, faster, AND cheaper (all three)
Claude Opus 4.5 has an "effort parameter" that lets you tune intelligence vs speed on the fly. Here's how it works →
Amit Arora
November 26, 2025

Welcome,
Ever wait forever for an AI to finish "thinking" only to get a mediocre answer?
Yeah, me too.
Anthropic just fixed that problem. And honestly? They might've just changed the entire game.
Claude Opus 4.5 dropped last week, and it's doing things that shouldn't be possible yet.
Here's the part that made me stop scrolling:
Anthropic gives prospective engineers a notoriously difficult 2-hour coding exam. It's so hard that most candidates fail. Senior engineers struggle with it.
Opus 4.5 scored higher than every single human candidate who's ever taken it.
Let that sink in.
But wait, it gets weirder (and better):
It's not just smarter. It's also faster AND cheaper than the previous version.
Usually, you pick two: fast, cheap, or smart. Anthropic said, "nah, here's all three."
So let's break down what actually changed, what it means for you, and why this might be the model you've been waiting for.
What Is Opus 4.5? (The Quick Version)
Opus 4.5 is Anthropic's flagship AI model, basically their smartest, most capable model yet.
Think of it like this:
Haiku = The fast, efficient one (quick tasks, high volume)
Sonnet = The balanced one (most people use this)
Opus = The genius one (hardest problems, deepest thinking)
What makes Opus 4.5 special:
It's the first AI model to break 80% accuracy on SWE-bench Verified—a brutal test where AI has to fix actual software bugs from real GitHub repositories.
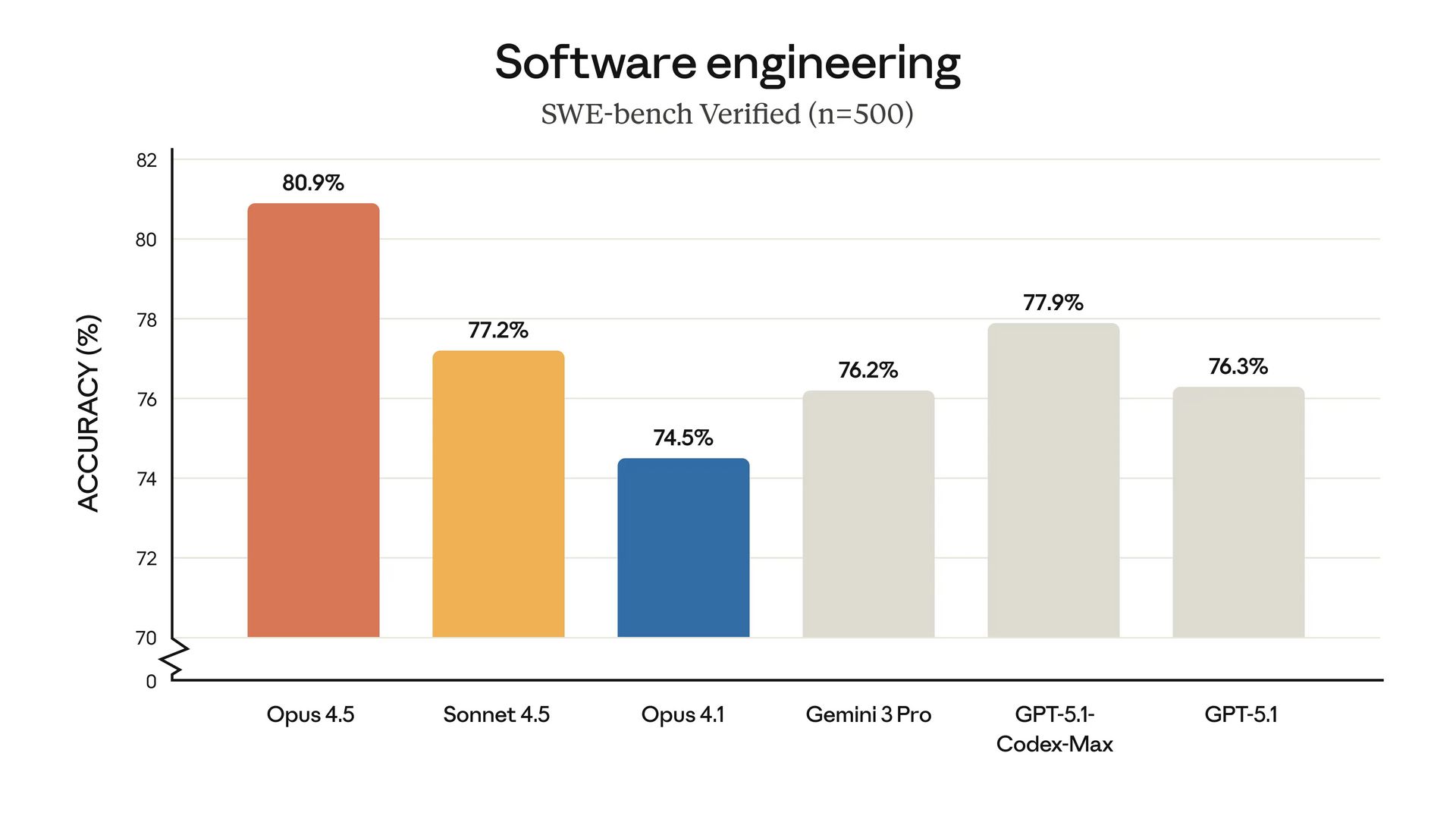
It can solve real-world coding problems better than any other AI. Period.
But here's the kicker: It costs one-third what previous Opus models cost.
So you're getting smarter, faster, AND cheaper all at once.
(When does that ever happen with technology?)
📊 The Benchmarks That Actually Matter
Okay, benchmarks are usually boring. But these numbers are actually wild:
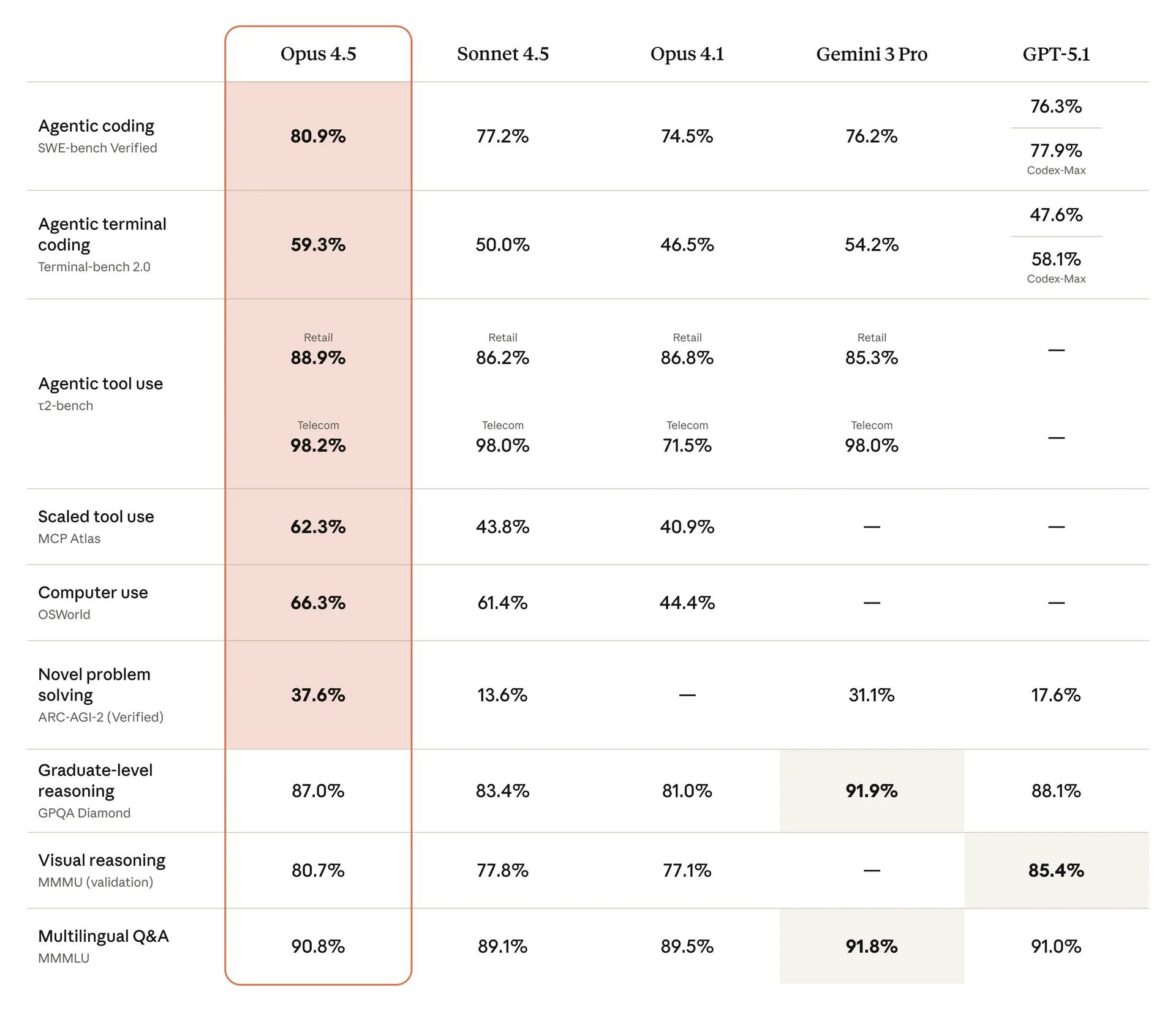
The ARC-AGI-2 score is the most important one here.
This test measures pure reasoning—problems the AI has never seen before and can't just memorise solutions to.
Opus 4.5 scored 37.6%.
GPT-5.1 was 17.6%.
That's not "slightly better." That's more than double.
What this actually means: Opus 4.5 isn't just better at what previous models could do. It can solve problems that other models literally can't figure out.
🧠 How It Actually Works
Opus 4.5 has two modes:
1. Standard Mode (Default)
Answers fast
Optimised for speed
Perfect for most tasks
2. Extended Thinking Mode
Takes its time to actually think
Shows you its reasoning process
Way more accurate for hard problems
Standard mode = That friend who interrupts you mid-sentence with an answer
Extended Thinking = That friend who says "hmm, interesting question, let me think about this" and then gives you a genuinely good answer
And here's the genius part:
Opus 4.5 automatically saves all its "thinking" throughout the entire conversation.
So if you're working on a complex problem over multiple messages, it remembers its entire reasoning chain. It doesn't forget what it figured out 10 messages ago.
(This seems obvious, but previous models didn't do this well.)
⚡ The "Effort Parameter"
This is new and honestly brilliant.
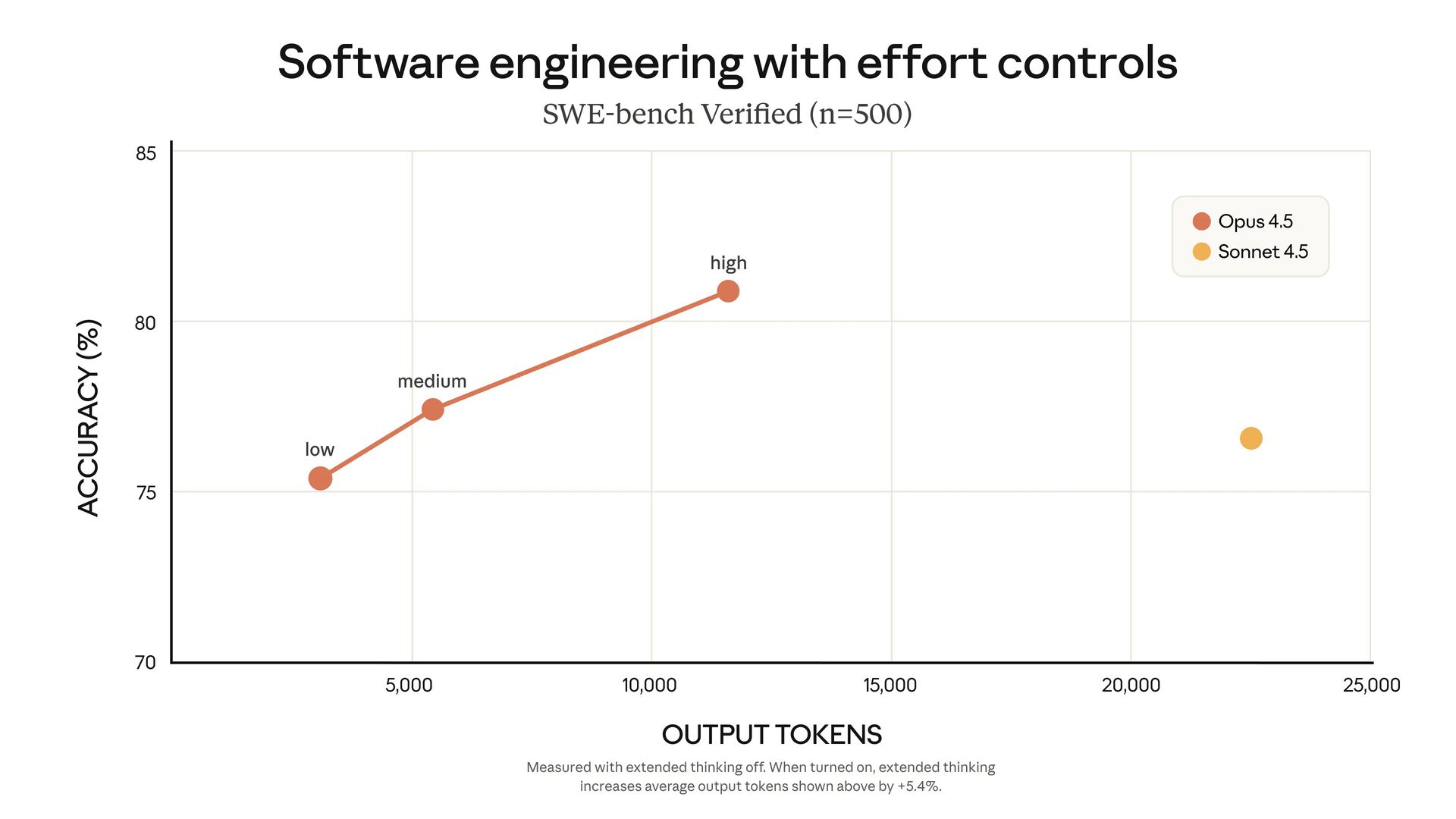
You can now tell Opus 4.5 how hard to try:
High Effort:
Maximum thoroughness
Best for complex analysis
Still uses 48% fewer tokens than Sonnet 4.5 while performing better
Medium Effort:
Balanced approach
Matches Sonnet 4.5's performance
Uses 76% fewer tokens
Low Effort:
Quick responses
Perfect for high-volume tasks
Most cost-efficient
Why this matters:
Before, you had to choose between different models based on task complexity.
Now? One model. You just dial the effort up or down.
It's like having a volume knob for intelligence.
Remember when I said it's cheaper?
Opus 4.5 costs:
$5 per million input tokens
$25 per million output tokens
That's one-third the price of previous Opus models.
Combined with the effort parameter, your real-world costs drop even more.
At medium effort, you get premium performance at a fraction of the cost.
Add in:
Prompt caching (up to 90% savings)
Batch processing (50% discount)
And suddenly, Opus-level intelligence becomes affordable for regular use instead of "save it for special occasions only."
🚨 The One Big Caveat
Extended Thinking Mode is slower.
When you activate it, expect longer response times. The AI is literally taking time to think.
Is it worth it? For complex problems, absolutely.
For quick tasks? Stick with standard mode.
Also, the 200K token context window is solid but not the biggest (Gemini 3 Pro has 1M).
For most tasks, 200K is plenty. But if you need to process entire codebases or massive documents, keep that in mind.
One Last Thing….
Opus 4.5 represents something rare: meaningful progress instead of incremental improvement.
The ARC-AGI-2 score alone (37.6% vs competitors at ~17-31%) proves this isn't just better engineering—it's qualitatively different reasoning capability.
Add in:
One-third the cost of the previous Opus
Effort parameter for tunable efficiency
Best-in-class coding performance
Genuine agent orchestration capabilities
And you've got a model that changes what's actually possible with AI.
The people who figure out how to use this effectively? They're gonna have a massive head start.
The rest will catch up eventually. But "eventually" might be 6-12 months from now.
Your call on which group you want to be in.
P.S. - Want to try Opus 4.5? Head to Claude.ai or grab API access at anthropic.com.
The free tier lets you test it out before committing.
Whether you use it or not is up to you.

Reply